
티스토리 뷰
정규화 (Normalization)
- 목표: 테이블 간에 중복된 데이터를 허용하지 않는 것이다.
- 중복된 데이터를 허용하지 않음으로 무결성을 유지
- null 값 최소화
-데이터 구조 안정성 최대화
* 무결성 : 데이터의 정확성, 일관성, 유효성이 유지되는 것
정규화 과정
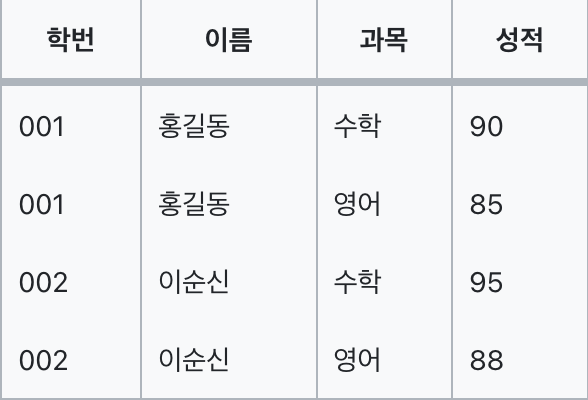
이 테이블을 보면 학번과 이름이 학생을 식별하는 기본키이지만 이름과 과목에 중복된 정보가 있다.
중복을 최소화 하기 위해 1NF, 2NF, 3NF, BCNF 등이 있다.

이와 같이 진행되며 보통 1NF ~ 3NF 까지 진행하거나 BCNF 단계까지 진행한다고 한다,
- 함수적 종속: X의 값에 따라 Y값이 결정될 때 X -> Y로 표현하는데, 이를 Y는 X에 대해 함수적 종속 이라고 한다. 예를 들어 학번을 알면 이름을 알 수 있는데, 이 경우엔 학번이 X가 되고 이름이 Y가 된다. X를 결정자라고 하고, Y는 종속자라고 합니다 다른 말로 X가 바뀌었을 경우 Y가 바뀌어야만 한다는 것을 의미한다.
- 함수적 종속에서 X의 값이 여러 요소일 경우, 즉, {X1, X2} -> Y일 경우, X1와 X2가 Y의 값을 결정할 때 이를 완전 함수적 종속 이라고 하고, X1, X2 중 하나만 Y의 값을 결정할 때 이를 부분 함수적 종속 이라고 한다.
- 함수적 종속에서 X,Y,Z 3개의 속성이 있을 때 X->Y Y->Z일 때 X->Z가 가 성립될 때 이행적 함수 종속이라고 한다.
1NF
테이블이 1NF를 만족했다는 것은 아래 세가지 조건을 만족했다는 것이다.
1. 어떤 릴레이션에 속한 모든 도메인이 원자값으로만 되어 있다.
2. 모든 attribute에 반복되는 그룹이 나타나지 않는다.
3. 기본 키를 사용하여 관련 데이터의 각 집합을 식별할 수 있어야 한다.
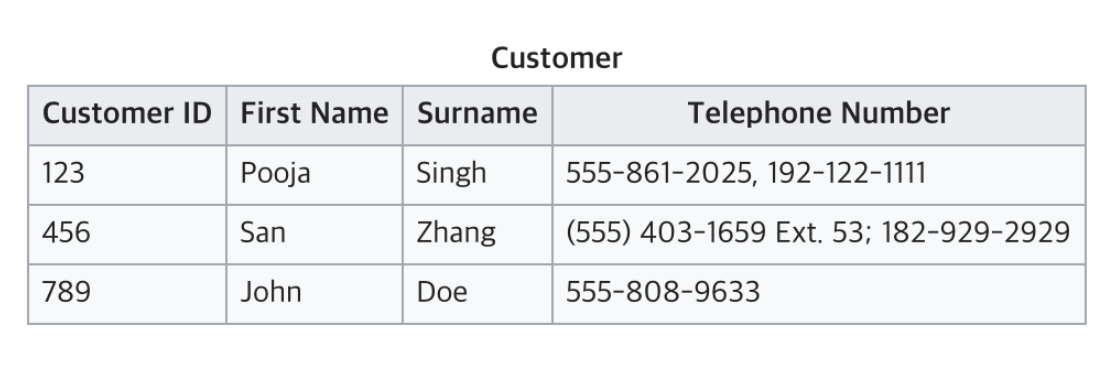
위의 테이블을 보면 여러개의 전화번호를 가지고 있기때문에 원자값으로만 되어 있어야 된다는 1번을 만족하지 못한 사례다.

위의 테이블을 본다면 전화번호 그룹이 반복되는 경우이며 2번을 만족시키못했어서 재 디자인 했지만, 더이상 ID가 기본키가 되지 않습니다.
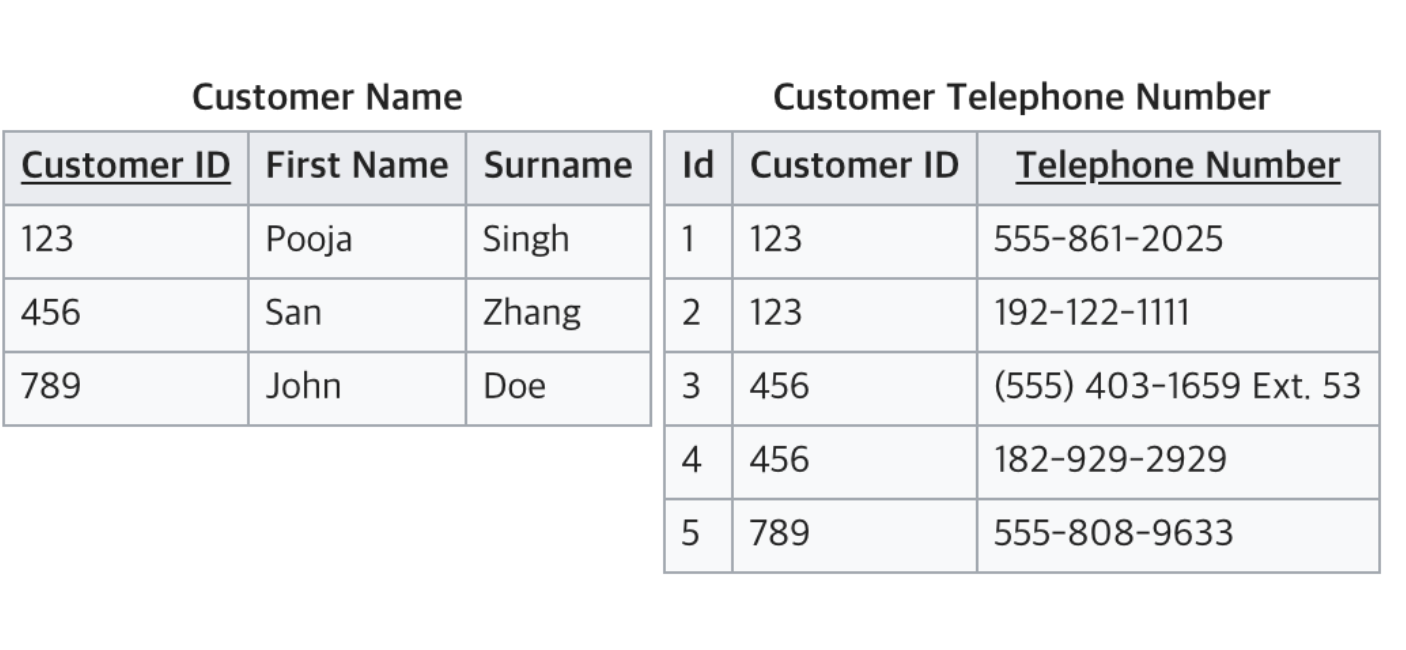
이 테이블은 customer 와 Telephone이 각자 테이블에서 기본키가가 되어 3번의 조건도 만족합니다.
2NF(부분적 함수 종속 제거)
-1NF를 만족하고, 완전 함수적 종속을 만족한다.

위 테이블을 보면, manufacterer과 model을 알면 model full name 필드를 참고하지 않아도 결정되기 때문에 {manufacterer,model}->model full name 이라는 함수 관계가 만들어 집니다. 하지만 manufacterer country는 model과는 아무런 관계가 없기 때문에 manufacterer와만이 종속 관계가 있고 이를 부분 함수 종속이라고 합니다.
부분 함수 종속을 제거 하기 위해서는 테이블을 두개로 만들어주면 된다.

3NF(이행적 함수 종속 제거)
테이블이 3NF를 만족한다는 것은 아래 두가지 조건을 만족하는 것이다.
1. 테이블이 2NF를 만족한다.
2. 기본키가 아닌 속성들은 기본키에만 의존해야 한다.

위 테이블을 보면 Tournament와 Year가 후보키가 된다.
Tournament -> Winner가 되고 Winner -> Winner Date of Birth이 되는데 이를 통해 Tournament -> Winner Date of Birth이 되는데 그럼 기본키가 아닌 Winner로 구분하는 상황이 되고 이행적 함수 종속 상태가 됩니다.

다시 테이블을 작성하면, 이행적 함수 종속 상태가 제거가 됩니다.
BCNF(Boyce-Codd Normal Form) 정규형
BCNF는 3NF를 만족하면서 모든 결정자가 후보키 집합에 속한 정규형이다.

위 테이블에서는 { 학생, 과목 }이 후보키가 되지만, 교수님이라는 제약이 있는 키가 있습니다. 교수는 한과목만 강의 할 수 있으니, 교수가 정해지만 과목이 결정이 된다. 그렇다면 교수가 슈퍼키가 되는데 이는 BCNF를 만족하지 못한다. ( 후보키가 아닌 '교수'가 결정자 역할 을 하고 있으니)

이렇게 테이블을 다시 짜게 되면, 교수가 담당하는 과목이 변해도 두개의 열을 갱신하지 않고 첫번째 테이블만 갱신하면 되고, BCNF를 만족하는 테이블이 된다.
비정규화 (반정규화 , de-normalization)
- 비정규화는 말 그대로 정규화를 시키지 않는 모델을 말하는게 아니다! 정규화를 진행시킨 다음, 필요에 의해 릴레이션을 합치는 등 데이터를 중복시키는 작업이다.
사용되는 시기
- 디스크 I/O가 많아서 조회시 성능이 저하 될 때
- 테이블끼리 경로가 멀어 조인으로 인한 성능 저하가 예상 될 때
- 칼럼을 계산해서 조회할 때 성능이 저하될 것으로 예상될 때
비정규화의 대상
- 자주 사용되는 테이블에 엑세스하는 프로세스의 수가 가장 많을 때
- 항상 일정한 범위만 조회 할 때
- 테이블에 대량 데이터가 있고, 큰 범위를 자주 처리할 때
- 성능 상 이슈가 있을 때
비정규화의 예시
- 정규화된 과목 테이블과 교수 테이블이 존재할 때 과목 테이블에는 교수의 이름은 들어가 있지 않고 교수의 ID만이 존재하기 때문에 과목테이블에 교수 이름을 치면 나오지 않게 된다. 그래서 join을 하게 되는 것임
단점
- 반정규화를 과도하게 적용하다 보면 데이터의 무결성이 깨질 수 있음(중복이 많아지니까)
- 입력 수정 삭제의 질의문에 대한 응답시간이 늦어질 수 있음 (모든 테이블의 데이터를 업데이트 삭제를 진행해야되서)
'cs 스터디' 카테고리의 다른 글
| [네트워크] 웹 동작 방식 (1) | 2024.01.21 |
|---|---|
| [네트워크] OSI 7계층 (1) | 2024.01.21 |
| [데이터 베이스] 이상현상 (0) | 2024.01.10 |
| [운영체제] CPU 스케줄링 (2) | 2024.01.05 |
| [운영체제] 프로세스와 스레드 (2) (0) | 2024.01.05 |